为什么你又在造轮子?
相信看到标题的人第一反应肯定就是为什么又是自制?为什么又要造轮子?没有现成的解决方案可以用吗?
额…现成的解决方案肯定是有的,相信现在各大公司除了自建日志平台,用得最多的应该是 elk 了吧。16 年的时候,我花了很多时间去学习 elk,当时 elk 还被称作是轻量级的日志解决方案,我也觉得 elk 是作为日志平台的首选。所以后来我在我自己买的云服务器上尝试安装 elasticsearch,我把内存配置为最小的 512M,虽然可以跑起来,但是几分钟之后就会挂掉,因为我的服务器只有 1G 内存。所以我觉得 elk 不适合于小微项目或者团队,而我一直以来也都是买最破最小的服务器来自己玩玩,明显也不适合使用 elk 这种对服务器有一定要求的日志解决方案。
但是再小的项目也都会产生日志,每次都上服务器查看文本日志似乎又不是很方便,所以后来我一直在找真正轻量级的日志解决方案,时间过去好几年,我了解到了 Loki ,这个日志解决方案给我最主要的印象就是只对日志做标签化处理,而不会做全文本的索引,这看起来就比较轻量化。但是在后续学习文档的过程中,我发现 Loki 的安装、配置文档相当简陋,很难完全明白如何使用,所以我没能在自己的服务器上试验一下是否能跑得起来。就这样我又开始等新的轻量级日志解决方案出现在我眼中。
2022 年,我在 github 上看到了一个自称可以作为 elasticsearch 的轻量级替代品的项目 Sonic ,听这名字就觉得很快的样子,而且是用 rust 开发的,感觉又快又稳啊。于是我赶紧翻阅了下文档,在 协议文档 中看到支持的命令竟然只有这么几个…我当时在想要是只做得这么简单,我上我也行。而且这个项目主要是针对全文检索,其实对于日志查询并不是一个太好的选择。当时翻阅着这个项目的文档,我突发奇想:如果我自己做一个功能像这样简单的日志解决方案呢,那凭我一个人完成度应该也能达到一个比较令我自己满意的水平了吧。
于是我就在脑海中开始想自己想要做一个怎样的项目,能达到怎样的效果,应该使用怎样的方式去实现。最终我花了差不多两个月的时间完成了 Talog 项目,目前项目基本已达到我所预期的效果,当然还有待完善。
Talog 是个怎样的轮子?
Talog 主要是借鉴了 Loki 将日志标签化的思想,并且会把具有相同标签的日志存放在同一个文件中。后续在查询日志时,通过指定标签来获取对应的日志文件,这种方式是简单高效的,但核心逻辑就是如此简单。当然仅通过标签来查询日志肯定是不足以满足大部分日志查询场景的,因此 Talog 还在核心逻辑上增加了一个扩展,后续会进一步介绍。除了查询日志,Talog 还能记录 PageView、Metrics,这两个功能在 elk 平台中,可以基于 elasticsearch 的数据,通过 Kibana 的仪表盘功能来实现。Talog 也是基于底层的标签化日志来实现这两个功能的,主要就是将数据视为一条条日志进行处理。
Talog 展示
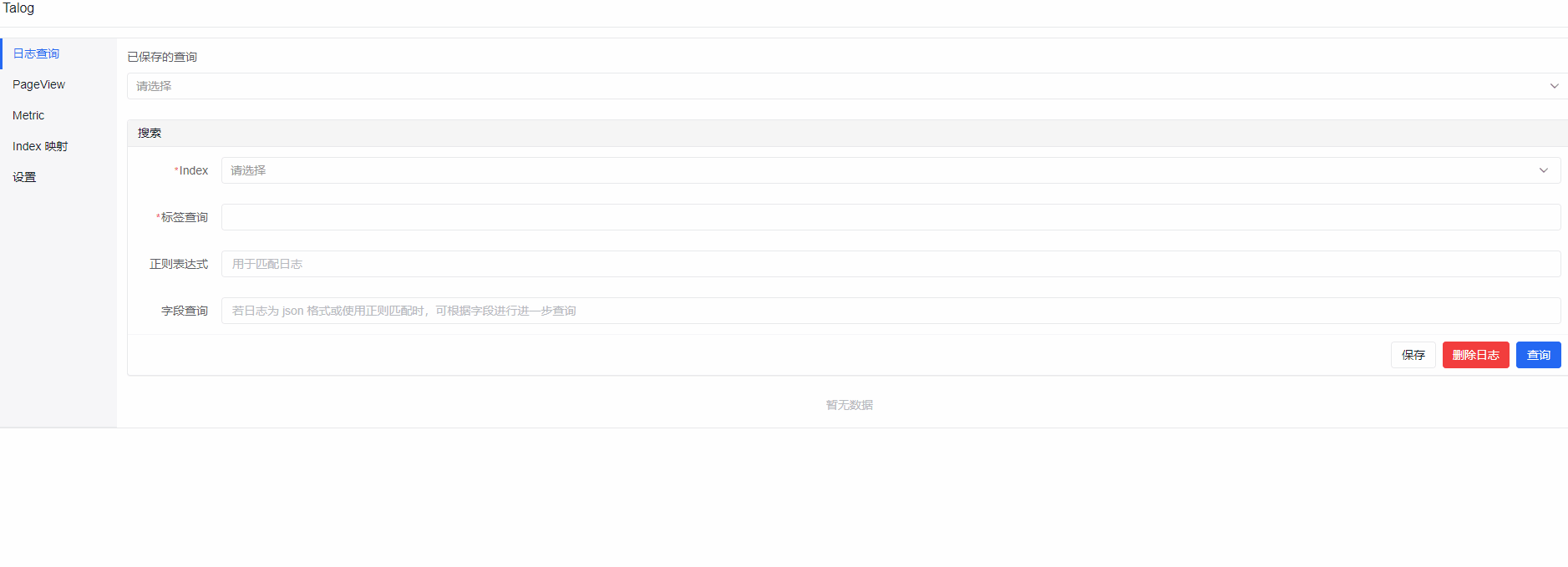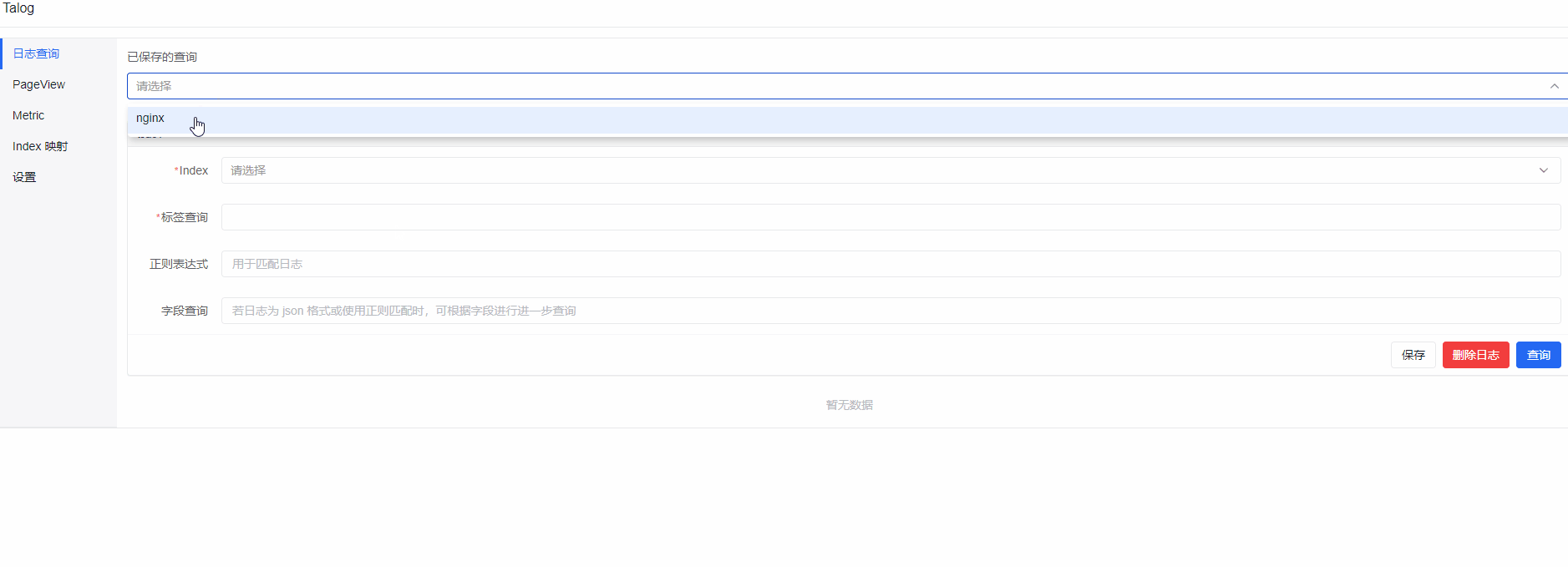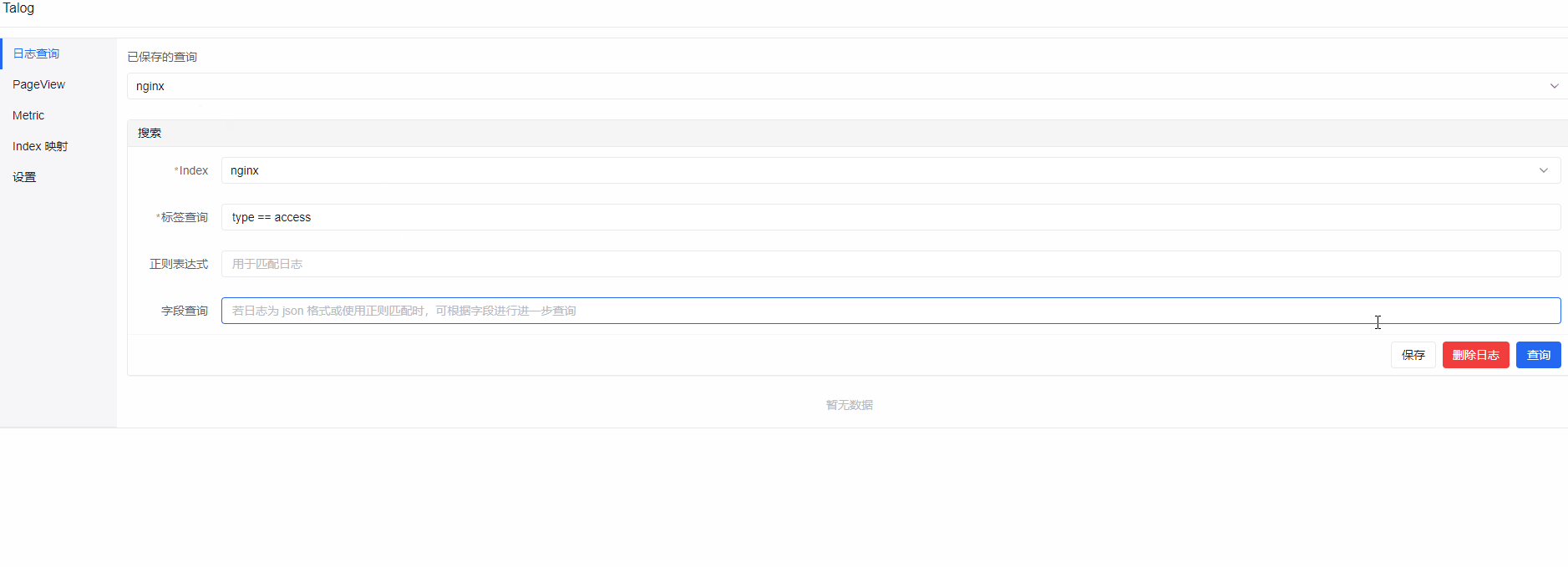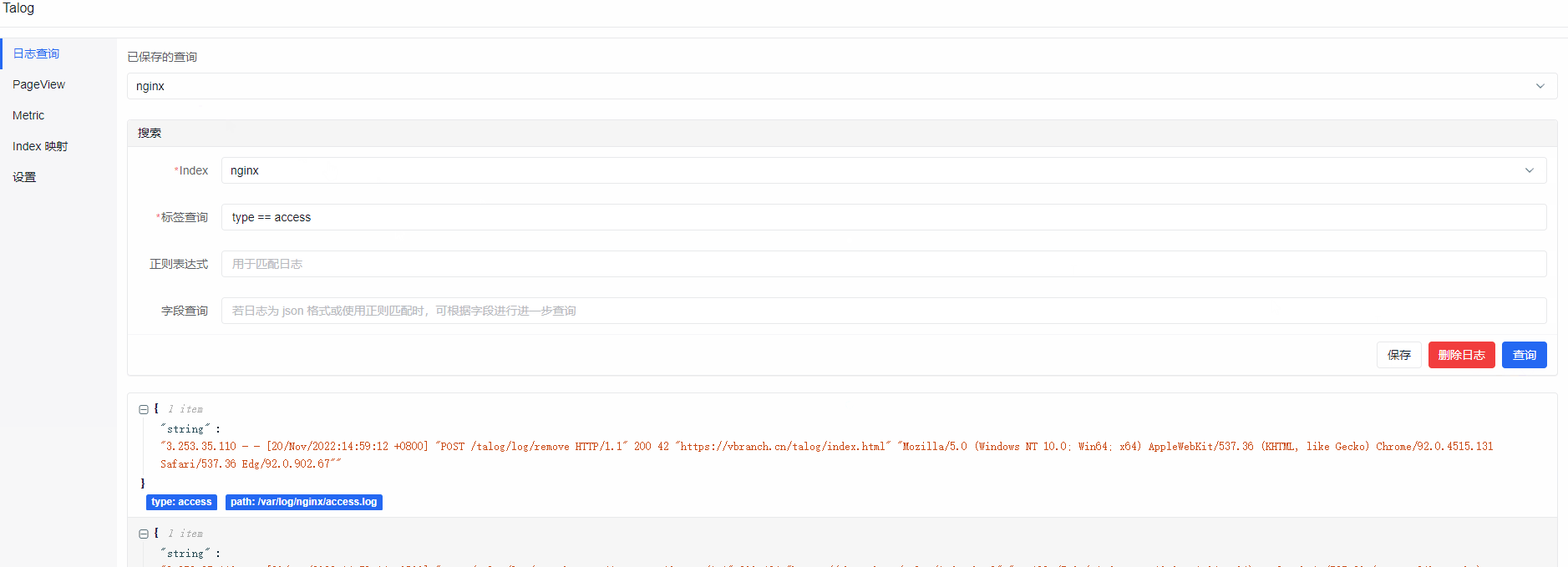

其实这三个动图在之前的文章就展示过了,懒得再重新制作了~
Talog 核心原理
在 Talog 中,一条日志可以有多种标签,Talog 会把标签完全一致的日志存放在同一个文件中,这个文件在 Talog 中被称为 Bucket。
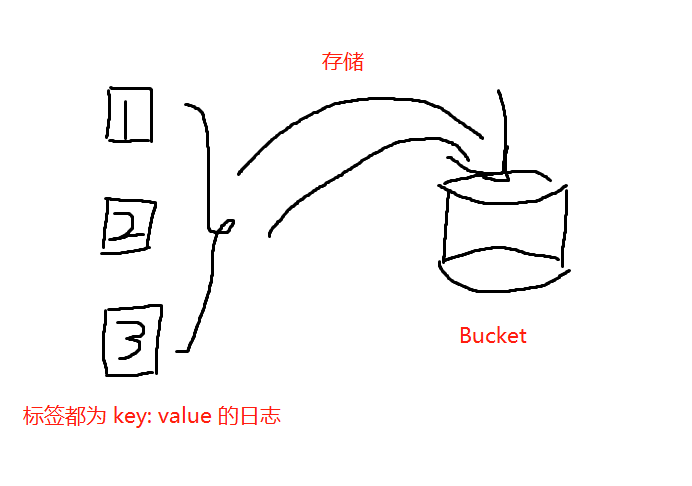
Talog 提供了一个叫 Index 的概念,以供用户将同一维度下的 Bucket(日志) 组织起来,这个维度可以是同一个项目或同一个业务。Index 会为每一种标签都建立一个字典树 Trie,这个字典树由标签的所有枚举值构建而成。
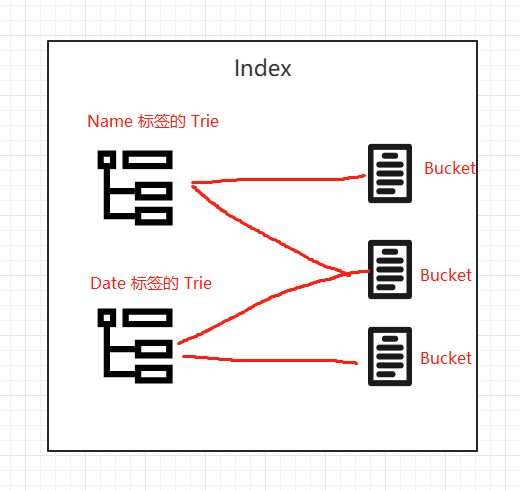

当你指定了某个标签,向 Index 请求查询相关日志时,Index 会找到对应标签的 Trie,查询标签值是否存在于 Trie 中,若存在则将相应节点的所有 Bucket 都取出来,这些 Bucket 所存放的日志即为指定标签的关联日志了。
因此在使用 Talog 时,需要对日志做好细致的标签化,来保证 Bucket 不会太大,从而导致日志读取速度缓慢,以及后续日志筛选处理效率低下。
最后
以上介绍了 Talog 的大体情况以及核心原理,下一篇文章会介绍一下 Talog 的日志索引过程。