上一篇文章简要介绍了一下 Talog 的核心原理,接下来将会对 Talog 的各个模块进行详细的介绍,本文先来介绍一下 Talog 中的日志索引。
太长不看
本文的介绍可能会较为繁琐、不好理解,因此先总结以下几个要点:
- Talog 追求简洁的 api 设计,
new Talogger().CreateIndexer("index name")即可创建日志索引器 - Talog 能保证日志数据不会丢失,但是可能导致多次索引
- Talog 默认的 Indexer 只支持单行日志
- 使用 HeaderIndexer 来支持多行日志
- 单线程一秒钟大致能索引 1100+ 条日志,多线程一秒钟大致能索引 1400 条左右
V.Talog.Core 核心包的索引过程
为了让 Talog 的 api 尽可能简洁,我设计了一个 Talogger 类,该类包含所有使用者可能会用到的入口,只要知道 Talogger 类的存在,就可以了解到 Talog 提供的所有功能。比如想要索引日志,只需要初始化 Talogger 类,然后调用 CreateIndexer 即可,而不需要关心用于索引日志的类名是什么。以下为具体的代码展示:
// Talogger 只有一个默认构造函数,想要修改 Talog 的配置,直接访问 Talogger.Config 属性即可
// Talogger 实现了 IDisposable,注销时会自动保存数据,因此建议使用 using 包裹相关业务代码,否则可能会丢失部分数据
// Talogger 以线程安全为目标进行设计开发的,所以全局只需要维护一个实例即可
using var talogger = new Talogger();
// 为每一条日志都调用一次 CreateIndexer 来生成日志索引对象
// 并且 api 支持流式调用,你可以一次性写完日志的所有初始化代码并保存,而不需要使用变量保存日志索引对象
// Talog 的设计就是希望足够简洁
// 虽然保存一条日志需要调用多次 Tag 方法、一次 Data 方法、一次 Save 方法,但这是为了让 api 灵活性而考虑的
talogger.CreateIndexer("index name")
.Tag("level", "info")
.Tag("time", DateTime.Now.ToString())
.Data("info log")
.Save();
以上代码中 Tag 方法以及 Data 方法都是在日志索引器(Indexer,后续为了方便主要使用该类名)内部实现的,真正与日志索引存储相关的是 Save 方法。调用 Save 时,Indexer 会将日志的标签列表以及日志文本发送给 Index 类,Index 的概念在上一篇文章中有提到,可以理解为是日志的逻辑集合,Index 对象由 Talogger 生成并传递给 Indexer,关于 Index 对象的初始化较为复杂后续会详细介绍,在此我们先关注日志索引过程。Indexer 把日志数据发送给 Index 是通过调用 Push 接口,Index 的 Push 接口虽然无法保证日志数据立即索引成功,但是可以保证日志数据不会丢失,这主要是因为 Push 接口会先将日志数据保存在 Index 的未索引日志列表(unsavedLogs)中,并立即将 unsavedLogs 序列化到磁盘中。
在将日志数据保存到 unsavedLogs 之后,Index 会先根据日志的标签列表获取对应的 Bucket 对象,Bucket 的概念上一篇文章也有介绍过,就是用于存储具有相同标签的日志数据的文件。
// tags 即为日志的标签列表,Bucket 的初始化过程主要就是依靠 tags 参数
// Bucket 会先根据标签名排序,然后使用 md5("key1:value1;key2:value2") 的计算公式来获取 Bucket 的 key
// Bucket 的文件名实际上就是 {key}.log
// 因此只要支持日志的标签列表就可以知道这条日志应该存储在哪个文件中
var bucket = new Bucket(this.Name, tags, this.config);
在 Index 获取到 Bucket 对象之后,会调用 Append 接口,将日志文本内容索引到磁盘中。到此,日志数据的索引就完成了一半,后续只需要在 Index 中对日志的元数据做维护即可。
元数据主要包括两部分:Bucket 以及字典树(Trie),Trie 的概念上一篇文章中也有提及,主要就是使用某一种标签的所有枚举值去构建一棵字典树。对于 Bucket 的维护相对比较简单,就是根据 Bucket 的 key 判断是否已存在于 Index 中(就是 Index 是否已经知道 Bucket 的存在),若不存在则添加到 Bucket 列表中。对于 Trie 的维护,就是遍历日志的标签列表,根据标签名从 Index 的 Tries 字典中获取对应的字典树(不存在的话,直接调用 new Trie() 初始化),然后调用 Trie 的 Append 方法,将标签值以及日志存放的 Bucket 对象存到字典树中。Trie.Append 会根据标签值找到对应的节点,并将 Bucket 存储在 Bucket 字典中(根据 Bucket.Key 去重)。
关于字典树的用途以及结构,读者可以自行搜索,该数据结构我是在大三找暑假实习的时候,一位百度面试官跟我说的,不然大学课程并没有教过该数据结构,在此感谢一下这位面试官,因为当时我的能力明显不合格,但是面试官还耐心地跟我介绍了一下这个数据结构。
至此,一个完整的 Talog 日志索引过程就介绍完毕了。
Index 的初始化
Index 的初始化主要依赖于使用者传递给 Talogger 的 index name,若 Index 是第一次初始化,会自动生成元数据文件,若不是第一次初始化,则会从磁盘中读取元数据文件,还原之前所保存的状态,并且会自动对上次未索引完成的数据进行再次索引(该机制有可能会导致日志数据多次索引,比如日志索引成功后,但是元数据还未保存成功时,程序意外中断)。以下将对这两种情况分别进行详细介绍。
假设首次运行依赖 Talog 的程序并且初始化名为 test 的 Index,则首先会创建 /data 目录,该目录名由 Talogger.Config.DataPath 指定,随后会创建 /data/test 目录,该目录用于存放 Index 的所有关联文件,然后会初始化 Index.Tries、Index.Buckets、Index.unsavedLogs 三个属性。
假设非首次初始化名为 test 的 Index,则会直接从 /data/test/index.json 读取元数据,该文件反序列化后主要有两部分数据:Index.Tries、Index.Buckets,Index.unsavedLogs 数据是单独存放在 /data/test/unsaved.json 文件中的,分成两个文件存储的主要原因是存储时机不同。Index.Tries、Index.Buckets 的存储发生在 Index.Save 方法被调用的时候,该方法主要是由 Talogger 的自动保存线程所调用。Index.unsavedLogs 数据的存储是发生在日志索引时,前面有提到,Talog 的日志索引第一件事,就是将日志数据保存在 Index.unsavedLogs 中,同时将数据序列化到磁盘中。
HeaderIndexer
HeaderIndexer 类是在 V.Talog.Extension 包中实现,主要是为了支持多行日志而设计,但其实与 Indexer 的区别只在于 HeaderIndexer 会在每一条日志添加一个 [{head}] 前缀,用于标识新日志文本的开头。以下为使用 Talogger 对象创建 HeaderIndexer 的扩展方法签名:
/// <summary>
/// 创建 HeaderIndexer
/// </summary>
/// <param name="talogger"></param>
/// <param name="index"></param>
/// <param name="head">若 head 为 null,则默认使用 index 作为 head</param>
/// <returns></returns>
/// <exception cref="ArgumentNullException"></exception>
public static HeaderIndexer CreateHeaderIndexer(this Talogger talogger, string index, string head = null)
使用以下代码来快速开始使用 HeaderIndexer:
new Talogger().CreateHeaderIndexer("test_header")
.Tag("level", "info")
.Tag("time", DateTime.Now.ToString())
.Data("info\nlog")
.Save();
JsonIndexer
JsonIndexer 本质上与 Indexer 一致,因为正常 json 序列化都是采用压缩格式,字符串只占一行,应该不会有人不是采用压缩格式做 json 序列化的吧,不会吧,不会吧。如果是那在 Talog 中应该使用 HeaderIndexer 进行索引。主要是为了与 JsonSearcher 相对应,所以特意创建了 JsonIndexer 类,该类在 Indexer 的基础上仅增加了一个接口,用于支持传入复杂日志对象。
public JsonIndexer Data<T>(params T[] ts)
{
this.data.AddRange(ts.Select(t => JsonConvert.SerializeObject(t)));
return this;
}
索引后的日志文件结构展示
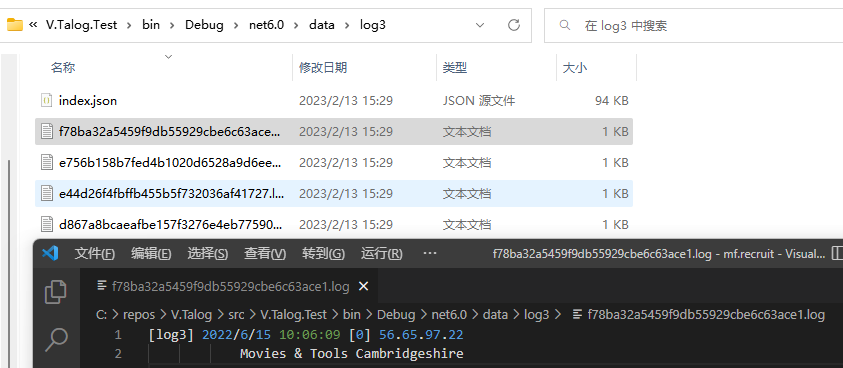
除了存放日志的文件是使用 Bucket 的 key 命名的,其他文件结构、文件内容均是人类可读的,这有利于了解 Talog 的运行机制以及异常排查。
索引效率
以下为我在笔记本上做的不完全测试,因为同时还有其他程序在运行,所以以下结果仅供参考。测试过程中的每一条日志平均为 80 字节,CPU 为 Intel i7-1065G7 @ 1.30GHz 4 核 8 线程,硬盘为东芝 256G 固态硬盘。
| 单线程 | 多线程 | |
|---|---|---|
| 索引 1W 条日志 | 耗时 21s(476 条/s) | 耗时 17s(588 条/s) |
| 索引 5W 条日志 | 耗时 1m53s(442 条/s) | 耗时 1m34s(531 条/s) |
| 索引 10W 条日志 | 耗时 4m3s(411 条/s) | 耗时 3m11s(523 条/s) |
| 索引 20W 条日志 | 耗时 7m44s(431 条/s) | 耗时 6m49s(488 条/s) |
从以上数据可以看出单线程一秒钟大致能索引 400+ 条日志,多线程一秒钟大致能索引 500 条左右,从单线程变更到多线程,似乎索引速度并没有得到太大的提升,这个可能是因为 Talog 的索引瓶颈在于文件的读写。这速度估计是根本无法和市面上的日志平台相比的,但是对于 Talog 的定位(面向小微项目的单机日志解决方案)而言,这个索引效率应该是已经达到可以使用的水平了。
优化索引速度
在测试了索引效率之后,并不是很满意这个索引速度,并且在知道优化方向的情况下,我果断又花了点时间去优化了下代码。
并且换了一台笔记本进行测试,CPU 为 Intel i5-12450H 8 核 12 线程,硬盘为西部数据 512G 固态硬盘。
| 单线程 | 多线程 | |
|---|---|---|
| 索引 1W 条日志 | 耗时 8s(1250 条/s) | 耗时 5s(2000 条/s) |
| 索引 5W 条日志 | 耗时 45s(1111 条/s) | 耗时 34s(1470 条/s) |
| 索引 10W 条日志 | 耗时 1m30s(1111 条/s) | 耗时 1m8s(1470 条/s) |
| 索引 20W 条日志 | 耗时 2m56s(1136 条/s) | 耗时 2m27s(1360 条/s) |
| 索引 30W 条日志 | 耗时 4m27s(1123 条/s) | 耗时 3m29s(1435 条/s) |
可以看到优化后的效果比之前的版本好了许多,主要是通过使用 FileStream 代替 System.IO.File,并且使用读写锁代替 lock 的方式来提高效率。目前单线程一秒钟大致能索引 1100+ 条日志,多线程一秒钟大致能索引 1400 条左右,这个速度对于小微项目绝对是达到可以用的水平了吧。
最后
本文介绍了 Talog 的日志索引过程的所有细节,也许随便一个开源项目的复杂度就能够吊打 Talog,但是 Talog 设计之初就明确了目标——小微项目、够用就行。下一篇文章将会介绍一下 Talog 的日志查询部分。