上一篇文章介绍了 Talog 的日志索引,本文来介绍一下日志查询部分的逻辑。
太长不看
- 使用 Query 类构建查询表达式
- 日志搜索器主要依赖字典树进行查询,查询结果实质为 Bucket 列表,速度很快
- 复合查询实际上就是对 Bucket 列表做交集、并集操作,速度很快
- 使用 HeaderSearcher 来查询多行日志
- “合理"的日志标签才能发挥出 Talog 的性能,相反,“不合理"的日志标签会让 Talog 表现得特别糟糕
日志查询底层逻辑
首先,还是先从展示如何从 Talogger 创建日志搜索器入手:
using var talogger = new Talogger();
List<TaggedLog> logs = talogger.CreateSearcher("index name")
.SearchLogs(query);
日志查询的主要代码逻辑就如以上所展示的一样简单,但是 query 查询的构建就会稍微复杂一点。
在 V.Talog.Core 核心包中,只能通过 Query 对象来构建查询表达式,最基础的查询 key=vlue 可以使用 new Query("key", "value") 来构建,这个初始化操作会将 Query.Tag 设置为 {"key": "value"},并且将 Query.Type 设置为 0。仅当 Query 为基础查询时,Tag 属性才会有值,而 Query.Type 属性支持 4 种枚举值:
- 0 eq 仅当 Query 为基础查询时,才有肯能出现该枚举值。表示需要查询 Query.Tag.Label == Query.Tag.Value 的数据
- 1 neq 仅当 Query 为基础查询时,才有肯能出现该枚举值。表示需要查询 Query.Tag.Label != Query.Tag.Value 的数据
- 2 and 仅当 Query 为复合查询时,才有肯能出现该枚举值。表示需要查询 Query.Left && Query.Right 的数据
- 3 or 仅当 Query 为复合查询时,才有肯能出现该枚举值。表示需要查询 Query.Left || Query.Right 的数据
上面所提到的 Query.Left、Query.Right 主要用于构建复合查询,例如 new Query("key1", "value1").And(new Query("key2", "value2")) 会生成一个新的 Query 对象(以上提及的三个 Query 对象分别称为 query1、query2、query3),其中 query3.Left 就是 query1,query3.Right 就是 query2,query3.Type 则等于 2。
之所以要花这么多篇幅介绍查询表达式的构建,主要是为了后续介绍日志查询逻辑做铺垫。Talog 设计的日志存储方式是根据日志的标签来组织的,因此查询时也主要是通过标签来进行查询,而日志查询所用到的主要数据结构就是日志索引时所构建的字典树,日志查询器(后续简称为 Searcher)使用用户传入的查询表达式中的标签,在字典树中查找对应的节点,这些节点上的 Bucket 列表即为搜索结果。没错,在 V.Talog.Core 核心包中,日志查询本质上就只是查询到对应的日志文件,不会再做进一步的细致化处理。关于对日志文件中的所有日志做筛选,在后续的文章中会给大家介绍。在此,我们先来详细分析一下 Searcher 根据查询表达式查询日志的过程。
当用户传入的查询表达式为基础查询时,Searcher 会将 Query.Tag 传递给 Index,让 Index 找出对应 Bucket 列表,此处出现的 Index 是在 Talogger 初始化 Searcher 的时候,由 Talogger 传递给 Searcher 的,这个逻辑与上一篇文章中的 Indexer 一致。看过日志索引逻辑的读者应该还记得,Index 中维护了很多标签的字典树,当 Searcher 将 Tag 对象传递给 Index 后,Index 会根据 Tag.Label 获取到对应的字典树,然后找到字典树中 Tag.Value 所对应的节点,并且把这个节点上的 Bucket 列表返回给 Searcher。以上逻辑就是 Searcher.Search 方法的逻辑,Search 方法只会返回 Bucket 列表,而如果想要获取到日志数据,则可以调用 SearchLogs,该方法只是在调用完 Search 方法之后,从 Bucket 读取日志文本。这样,一次基础查询的查询过程就介绍完毕了。
当用户传入的查询表达式为复合查询时,Searcher 会递归调用 Search 方法,获取到 Query.Left 以及 Query.Right 所对应的 Bucket 列表(两个列表分别称为 buckets1、buckets2)。然后,当 Qeury.Type 等于 2 时,则求得 buckets1、buckets2 的交集(在 .net 中直接使用 linq 的 Intersect 方法)即为结果;当 Qeury.Type 等于 3 时,则求得 buckets1、buckets2 的并集(在 .net 中直接使用 linq 的 Union 方法)即为结果。
HeaderSearcher
HeaderSearcher 类是在 V.Talog.Extension 包中实现,主要用于查询多行日志,与 Searcher 类的唯一区别在于 HeaderSearcher 重写了 SearchLogs 方法,因为 Searcher.SearchLogs 会将每一行识别为一条日志,而 HeaderSearcher 会逐行读取日志,并在 [head] 标识出现时,才会认为出现了新的一条日志数据。
JsonSearcher
JsonSearcher 在 Searcher 的基础上添加了两个接口,主要就是将日志反序列化成复杂对象。
public List<TaggedJsonLog<JObject>> SearchJsonLogs(Query query)
{
var logs = this.SearchLogs(query);
if (logs == null)
{
return null;
}
return logs.Select(x => new TaggedJsonLog<JObject>
{
Tags = x.Tags,
Data = JsonConvert.DeserializeObject<JObject>(x.Data)
}).ToList();
}
public List<TaggedJsonLog<T>> SearchJsonLogs<T>(Query query)
{
var logs = this.SearchLogs(query);
if (logs == null)
{
return null;
}
return logs.Select(x => new TaggedJsonLog<T>
{
Tags = x.Tags,
Data = JsonConvert.DeserializeObject<T>(x.Data)
}).ToList();
}
查询效果展示-极端情况
先展示一个比较极端的测试用例,沿用上一篇文章索引日志时的测试代码,但是上一篇文章只使用了日期以及日志等级来作为标签,本次加上了 IP,因为日志数据都是用 Bogus 随机生成的,因此 IP 基本不存在重复的情况。我这次生成了 20W 条日志,也对应生成了 20W 个日志文件,每个日志文件仅存放一条日志,此时的索引文件达到了 253M。

本次测试用到的查询表达式较为简单,就是查询日志等级为 0 的所有日志,可以预见查出来的日志文件肯定很多,因此在此就不读取日志文本内容,而是只查询对应的 Bucket 列表展示查询效果。
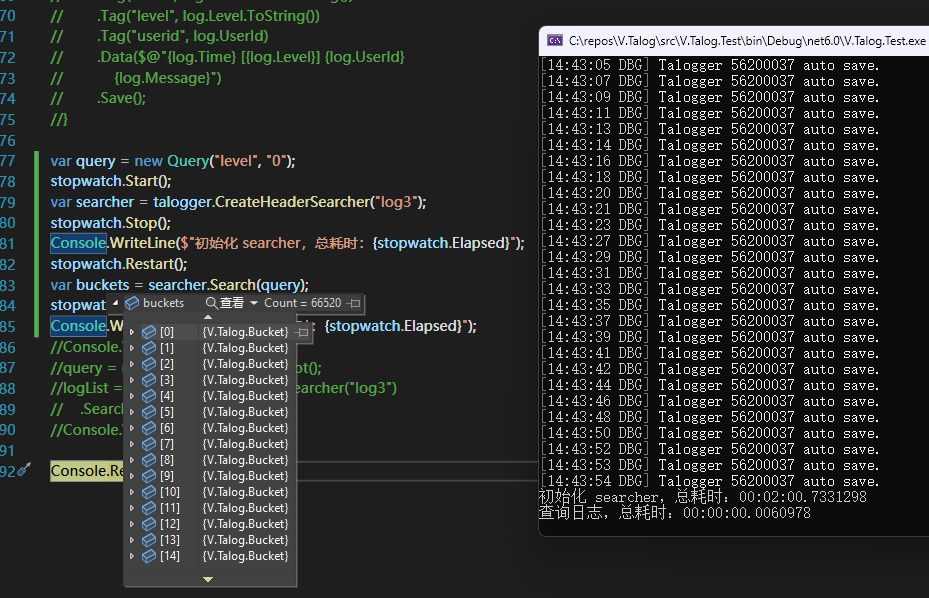
从上面的运行日志来看,加载索引文件初始化 Searcher 就花费了 2m 的时间,当然这跟测试笔记本的环境有关(和之前一样,也是在运行其他程序…),这说明了在 Talog 中,给日志打上"不合理"的标签,会带来特别严重的效率问题。而日志查询只花费了 6ms 的时间,就能查出 6W+ 条结果,这主要归功于字典树这个数据结构。
查询效果展示-正常情况
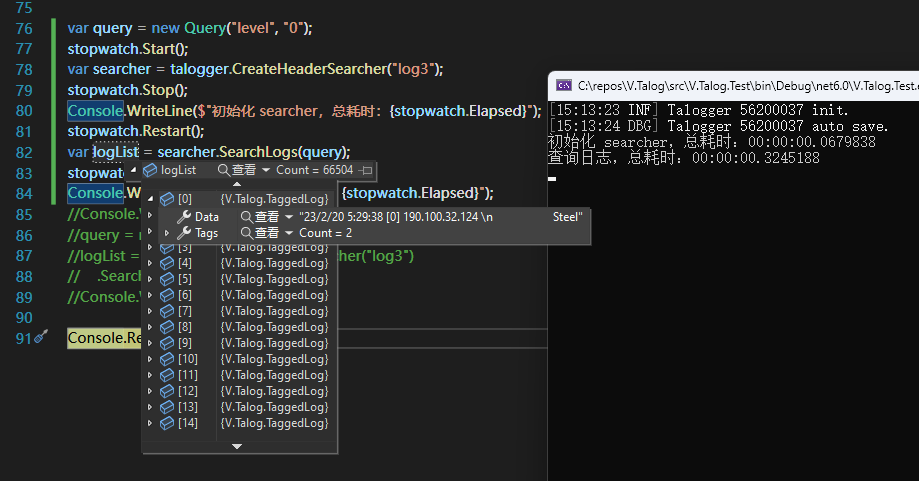
本次测试不对日志打 IP 标签,随机生成 20W 条日志,此次生成的日志文件变成 18 个,索引文件大小为 15K。

日志查询表达式同上,初始化 Searcher 的时间仅花费 68ms,改为调用 SearchLogs 方法查询日志文本,消耗 324ms。日志查询的耗时主要在于日志文件的读取与解析,后续可以对这方面进行优化,但是日志查询的应用场景一般都是问题排查,日志查询速度应该可以不用特别快,只要能够在 1~2s 内返回即可,个人感觉。
最后
Talog 的日志查询性能对于小微项目来说,绝对是够用的,但是想要利用好 Talog 具有一定的门槛,那就是,需要考虑清楚如何"合理"地给日志打上标签。本文介绍的 Talog 查询能力,只能提供一个比较基础、粗略的效果,下一篇文章会介绍一下 V.Talog.Extension 扩展包为 Talog 提供的日志查询能力。